Hier einer der Posts zu meinem 2023. Dieser und andere Posts sind unter dem Tag jahresrückblick23 zu finden.
Christian hat mich daran erinnert, dass ich noch darüber schreiben wollte, wo ich dieses Jahr war.
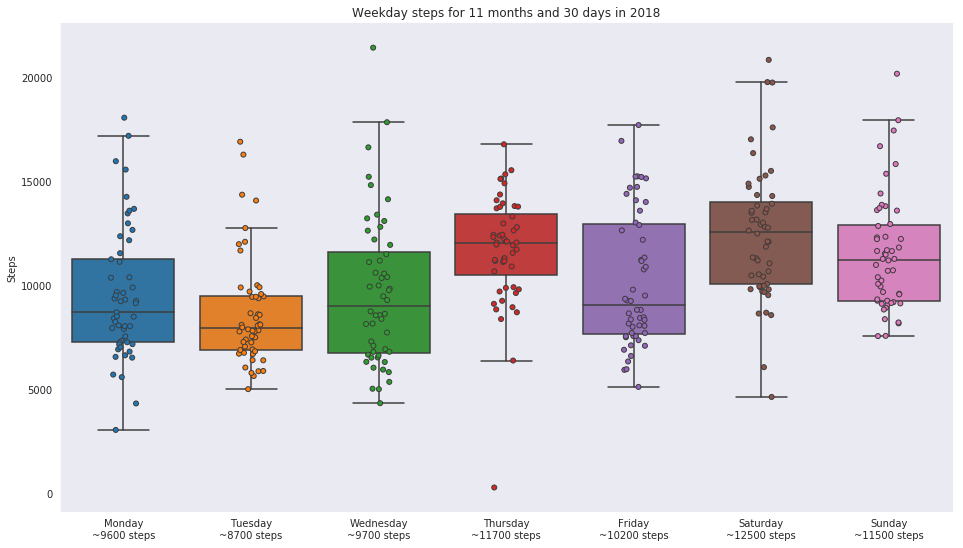
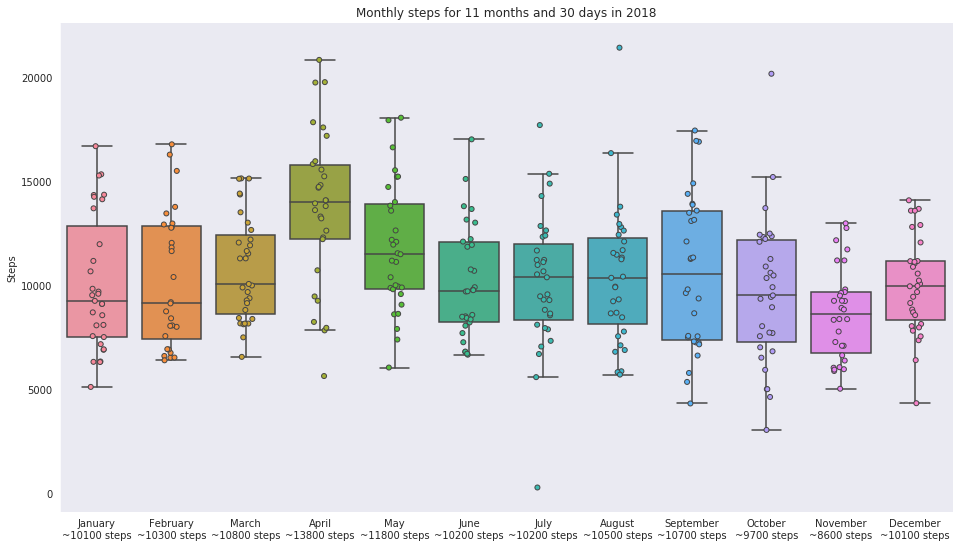
Dank dem ‘Premium’-Abo von WHIB habe ich einen Überblick der Positionen meines Telefons während der letzten 5 Jahre in einer CSV-Datei, die mit etwas Python-Code einfach auswertbar ist.
Schlussendlich habe ich 20700 Datenpunkte mit einer Position im 2023.
Ich schalte mein Telefon in der Nacht aus, also habe ich im Schnitt (bei 8h ausgeschaltetem Telefon) ca. alle 20 Minuten einen Datenpunkt.
Im Sommer sind wir mit unserer fahrenden Ferienwohnung an der Atlantikküste gewesen, haben auf lustigen, eigentlich privaten Campingplätzen übernachtet und viel unsere mitgenommenen Velos bewegt.
Im Herbst haben wir die Nordostküste von Sardinien befahren und waren so viel wie möglich nicht auf Campingplätzen, sondern haben am Strand übernachtet, bis der Strom und Kühlschrank leer und das WC voll waren.
Wir sind insgesamt 910 km in Nord-Süd, und 893 km in Ost-West-Richtung unterwegs gewesen.
Im Median war ich auf dem Bänkli beim Elefantenspili.
Am nördlichsten waren wir etwas südlich von Paris, auf der Autobahn, am östlichsten irgendwo südlich von Bastia in Korsika (wo wir nicht waren, und sich wahrscheinlich mein Handy bei der Fährüberfahrt von Genua nach Porto Torres eingebucht hat), am südlichsten irgendwo nach 3 Nächten am schönsten Strand von Sardinien (Is Arutas, der uns von zwei wunderbaren alten Menschen ein paar Nächte vorher empfohlen wurde), am westlichsten irgendwo auf dem Weg zum Strand auf Noirmoutier.
Der höchste Punkt war zum Start in die Skisaison vor gut einem Monat auf dem kleinen Matterhorn in Zermatt.
Unten ist die Heatmap meiner Positionen im 2023 eingebunden, so dass Reinzoomen in die Karte und Raussuchen anderer Ausflüge selbst möglich ist.
Die komplette Analyse ist auf GitHub zu finden, falls jemand dies für sich nachbauen will.
Weil die Originaldatei mit meinen Positionen auch die genauen Zeiten enthält, liefere ich die aus datenschutztechnischen Gründen nicht mit.
Eine komplette Version meiner Analyse als Notebook mit allen Karten ist dank dem coolen NBViewer hier zu sehen.
Der nächste Jahresrückblick wird dann noch etwas spannender.
Wir planen von Mitte April bis Mitte Juli eine grosse Auszeit und werden mit den Kindern Nationalpärke auf einem anderen Kontinenten besuchen.