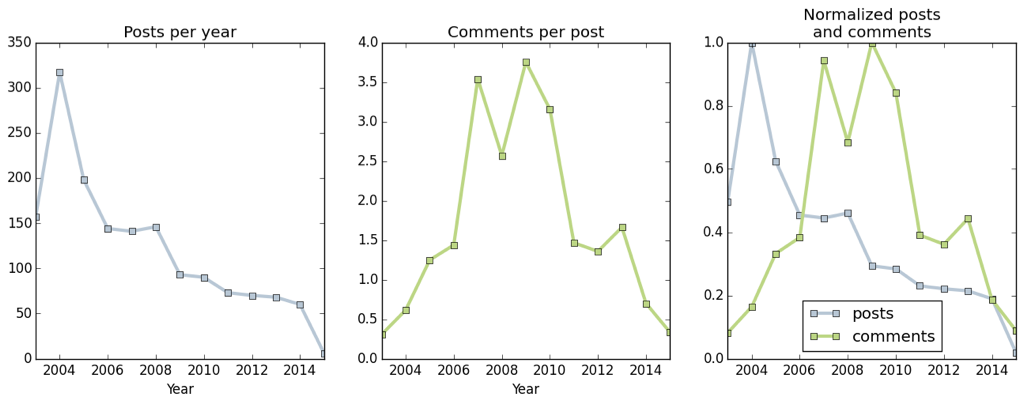
Wer mich ein bisschen kennt, weiss, dass ich einen OpenStreetMap-Fetisch habe.
Letzthin bin ich via WeeklyOSM auf EqualStreetNames gestossen.
Das Team von EqualStreetNames visualisiert, wie die Geschlechterverteilung der Strassennamen in einer Stadt aussieht, z.B. für Brüssel.
Das Team von EqualStreetNames hat eine Vorlage erstellt, damit eine solche Strassenbenamsungsgeschlechterverteilungsvisualisierung für jede beliebige Stadt erstellt werden kann.
Da ich Verknüpfungen von verschiedenen Datenquellen liebe und ’a sucker for nice visualizations’ bin, hab ich mir gedacht, das sollte doch auch für Bern gemacht werden.
Etwas später war die Vorlage angepasst und noch einen Moment später war https://bern.equalstreetnames.eu/ mit der Ersten nach dem Geschlecht der Namensgebebeerin visualisierten Strasse online, der Hardeggerstrasse.
Vor einer Woche hab’ ich dann ein paar OpenStreetMap-Aktive in Bern angeschrieben, ob sie mithelfen, die Strassen mit den notwendigen (und richtigen) name:etymology:wikidata-Tags zu versehen, damit diese Strassen dann in der Visualisierung auftauchen.
Dieser Tag beschreibt die Namensgeber*in in maschinenlesbarer Form, so dass automatisch das Geschlecht ausgelesen und visualisiert werden kann.
Eine Woche später haben mindestens thisss, ydrgbjo, freaktechnik, chatelao und orycteropus1 (sortiert in Reaktionszeitreihenfolge) mitgeholfen, dass von 908 Strassennamen in Bern schon 177 mit dem name:etymology:wikidata-Tag versehen sind [1].
Das Resultat der Arbeit ist hier zu sehen: EqualStreetNames.Bern.
Von den 177 Strassen, die bis jetzt eine*r Namensgeber*in zugeordnet sind, sind 151 nach einem Mann und 24 nach einer Frau benannt.
Die restlichen 731 Strassen sind entweder nach irgendwas sonst benannt, oder wurden noch nicht richtig zugeordnet.
Wer mithelfen möchte, am Repository für Bern rumzubasteln, oder dasselbe für ’seine’ Stadt nachzubauen möchte, kann sich gerne direkt bei mir melden.
[1]: Teilweise sogar mit zwei solchen Tags, wie die Tschäppätstrasse, die nach beiden Tschäppäts benannt ist.
PS1: chatelao hat von einer Bekannten aus der Politik eine Liste mit allen Strassenbeschilderungungen aufgetrieben, die wir mit Quellenangabe “Geodaten Stadt Bern” verwenden dürfen und in eine Tabelle abgefüllt.
PS2: ydrgbjo hat eine Wikimedia Commons-Kategorie erstellt; er und ich befüllen diese mit Strassenschilder-Fotos, damit unser Tagging nachvollziehbar ist.
PS3: Das Interdisziplinäre Zentrum für Geschlechterforschung der Uni Bern hat es in den zwei vergangenen Wochen noch nicht mal geschafft auf meine Mail-Anfrage nach Strassennamengeschlechteraufteilung zu reagieren, auch wenn der Barbara-Lischetti-Platz direkt vor deren Tür liegt :
PS4: Das Bild mit den Strassen von Bern im Header habe ich schnell mit der Hilfe von osmnx und dessen Beispiel-Notebook 7 gemacht…